When Blobs attack – understanding cloud storage bursts and viewing logs
- | Posted in
- amazon
- s3
- cloudfront
- azure
- s3stat
- cloud
- cloud storage
Here’s how it started…
Lisa (my wife) [shouting from office into the kitchen]: Tim, what’s this Amazon charge for $193?
Me [thinking what I may have purchased and not remembered]: Um, don’t know…let me look.
I then logged into my Amazon account to see what order I may have forgotten. Surely I didn’t order $200 worth of MP3…that’s ridiculous. Sure enough nothing was there. Immediately I’m thinking fraud. I start freaking out, getting mad, figuring out my revenge scheme on the scammer, etc.
Then it hit me: Amazon Web Services account.
The Culprit
Sure enough I logged in and my January 2010 billing account was $193 and change. Yikes. Well, I could let the (what has been averaging) $30 or so charge slide under the family CFO radar for a while…but this $193 charge…the chief auditor herself caught that one.
So I panicked. I needed to figure out where/what the spike was. I logged into the Amazon Web Services management console (I only use the S3/CloudFront storage in their services right no) to see what was going on. I see ‘Usage Reports’ and click. I’m met with essentially a bunch of useless data really. No offense to Amazon, but really the usage reports weren’t really helpful at all. First, they gave me a Resource ID which I thought would represent the URI I was looking for. Nope, Resource ID == Bucket. And they didn’t even put the bucket name in the report!
For some perspective, here’s essentially what I’m used to – here’s my December 2009 billing statement details:
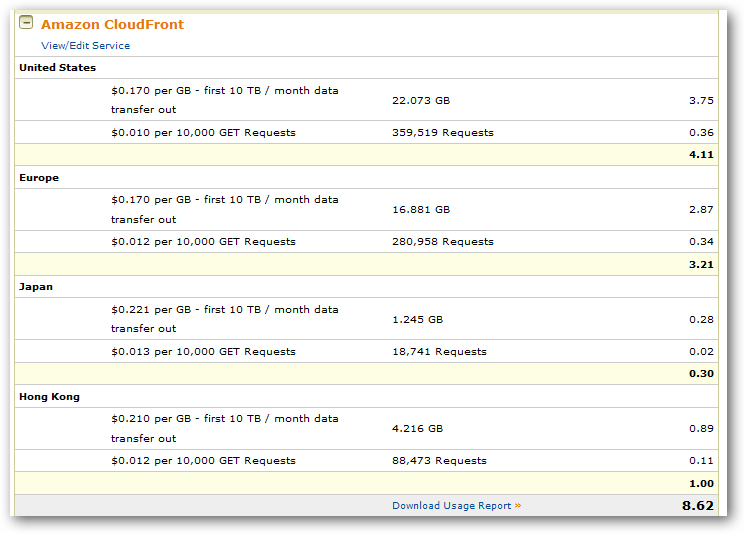
Anyhow, after some hunting it was obvious that I wasn’t going to figure out what bucket objects/unique URIs were causing my spike. This was primarily because I didn’t have logging turned on at all on my buckets. I had in the past but really didn’t think I needed it so I turned it off.
I was wrong – go now and enable logging.
While I was searching for a solution to understand my traffic, I was curious for where my traffic was. Like I said, I’d been averaging (actually *peaking*) at about a $30 charge for the S3 hosting.
NOTE: I use S3 for all my image/screenshot/sample code file hosting. I’ve invested in S3 for a long time and built my blogging workflow around it with building tools like S3 Browser for Windows Live Writer.
What was interesting was my most usage of my CloudFront data was coming from Hong Kong. Compare to above the December 2009 billing to this January 2010 billing:
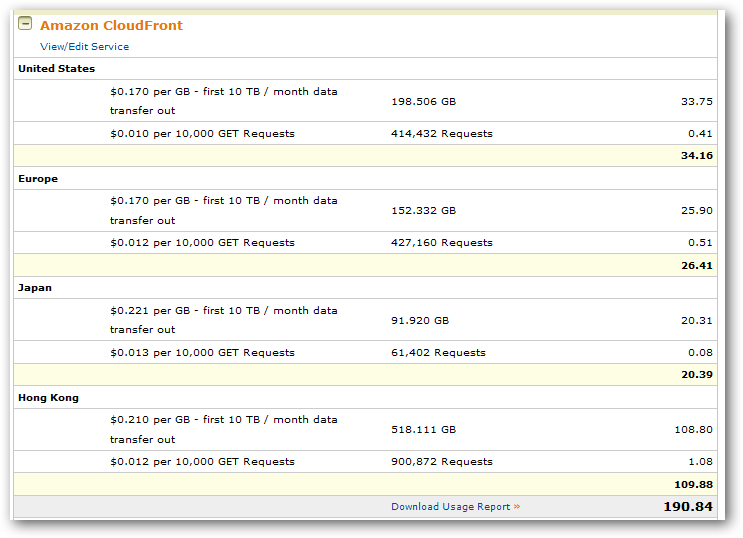
Yeah, that was my reaction too. I went from roughly 40GB of transfer bandwidth to over 960GB in one month. I suspected I knew what happened, but needed to confirm before I changed things.
Implementing Logging for Statistics
The problem was that I didn’t have logging enabled and I was pretty much stuck. I needed to get some data from the logs before being for sure. I quickly found S3Stat and it appears to be the de-facto reporting for Amazon S3 log files. I signed up for the free trial and generated a new access key to give them.
NOTE: They have a ‘manual’ option which means a lot more work. I simply generated a NEW S3 access key for this specific purpose. That way I didn’t have to give them my golden key I’ve been using in other places and can shut this off at any time without issue to my other workflows.
24 hours later, I had some reports. Wicked cool reports. Here’s a list of what I’m currently looking at:
- Total hits, total files, total kbytes
- Hits/files per hour/day
- Hourly stats
- Top 30 URIs
- Top URIs by kbytes used
- Top referrers (find out who’s using your bits without you knowing)
- User agents
- Here’s a quick snapshot of one:
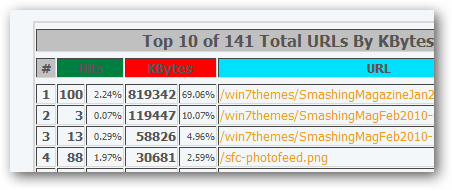
Wow…honestly…THIS is what I was expecting when I see “usage” data reports. S3Stat is awesome and you should use that now. Yes, I’m buttering up to them…but they have a great tool here for $5/month if you are a heavy Amazon S3/CloudFront user. Amazon frankly should just buy them and integrate this into their management console. You can see other examples of their report outputs on their site at http://www.s3stat.com.
What I also found out is that the tool I use for my desktop usage of S3/CloudFront (outside of my blogger workfow and S3Browser) has S3Stat integration built in! I use CloudBerry’s S3 Explorer Pro for managing my S3 content. It’s awesome and you should look at it. When I look at the logging features in CloudBerry I see this:
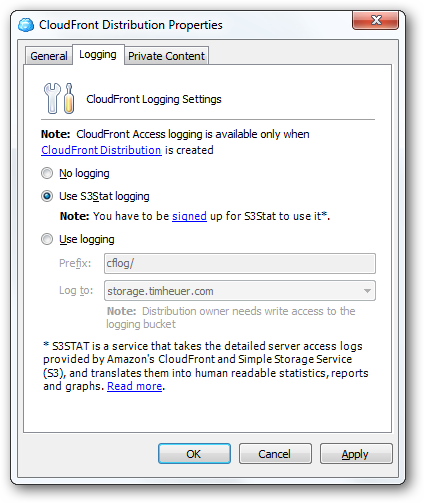
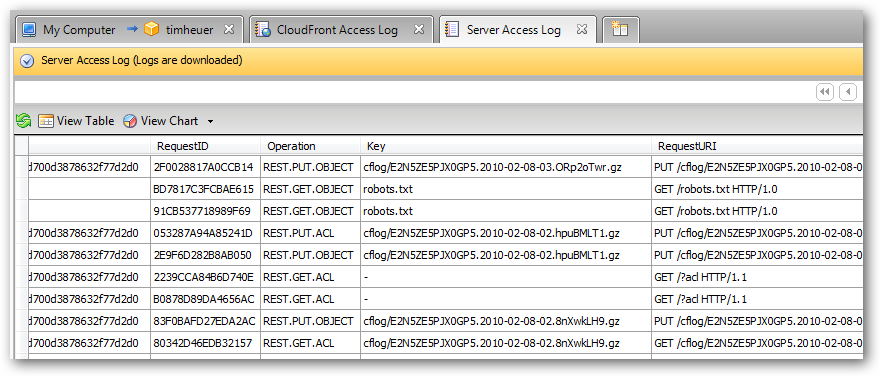
And after enabling the logging, within CloudBerry I can view the log data within the tool:
Summary
Wow, this is incredibly helpful and insightful data. I now know who/how/when my cloud storage data is being used in various ways I can see the data. S3Stat immediately showed me incredible value within less than 24 hours of enabling it. I know can confirm the culprit of the burst of usage and plan accordingly.
Now, to be clear I’m not complaining about the cost of cloud storage. That has been clear to me from the beginning. Nothing is hidden and I’m not an idiot for not understanding it. What I did not account for was the popularity of some files…and then the ones that just happened to be the largest. I could not have personally thought I’d see a 920GB spike in one month of usage…but now I know…and have to alter some plans.
Hopefully this is helpful for some who are just exploring cloud storage solutions/services. Make sure you have instrumentation and logging capabilities turned on so you can identify and tune your situations. For me, S3Stat and CloudBerry are winners for my personal usages. If you are an Amazon S3 customer, I recommend looking at S3Stat and turning on logging immediately!
Please enjoy some of these other recent posts...